Structure of the interpreter
The core of the interpreter is the intermediate representation (IR). This is how we represent IMP programs in memory. Since IMP is such a simple language, the intermediate representation will correspond directly to the syntax of the language; there will be a class for each kind of expression or statement. In a more complicated language, you would want not only a syntactic representation but also a semantic representation which is easier to analyze or execute.
The interpreter will execute in three stages:
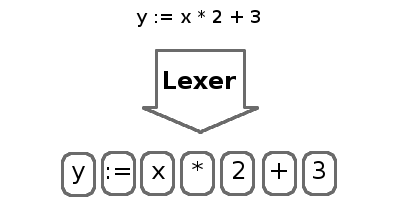
- Split characters in the source code into tokens
- Organize the tokens into an abstract syntax tree (AST). The AST is our intermediate representation.
- Evaluate the AST and print the state at the end
The process of splitting characters into tokens is called lexing and is performed by a lexer. Tokens are short, easily digestible strings that contain the most basic parts of the program such as numbers, identifiers, keywords, and operators. The lexer will drop whitespace and comments, since they are ignored by the interpreter.
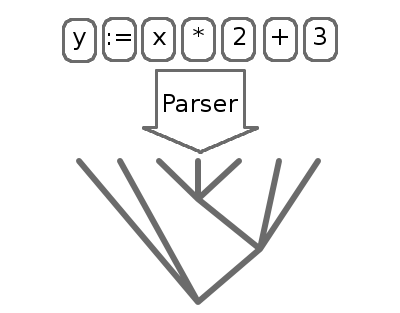
The process of organizing tokens into an abstract syntax tree (AST) is called parsing. The parser extracts the structure of the program into a form we can evaluate.
The process of actually executing the parsed AST is called evaluation. This is actually the simplest part of the interpreter.
This article will focus solely on the lexer. We will write a generic lexer library, then use it to create a lexer for IMP. The next articles will focus on the parser and the evaluator.
No comments:
Post a Comment